Rapport de recherche Analyse automatique de corpus de revues SHS
Ce rapport est conjointement publié sur le site du HN Lab qui a dirigé la présente expérimentation. Celle-ci s’inscrit dans la conclusion du projet Revue2.0 – Repenser les revues savantes en SHS porté par la Chaire de recherche du Canada sur les écritures numériques.
Dans le cadre des expérimentations de la phase 2 du projet, le HN Lab a lancé un chantier d’analyse sur les corpus de trois revues savantes afin de répondre aux problématiques suivantes :
Quel est l’apport scientifique d’une revue ?
Quels sont les concepts qui ont traversé l’histoire d’une revue ?
Comment situer une revue scientifique dans son champ de recherche ?
Pour traiter de ces questions complexes, l’expérimentation consistait à éprouver et à comparer différentes méthodes d’analyse automatique de textes, notamment les méthodes de machine et deep learning (ML/DL), méthodes qui ont permis d’apporter quelques éléments de réponses.
L’expérimentation a également été l’occasion de confronter ces méthodes ML/DL aux propres méthodes d’analyse et d’enrichissements sémantiques employées par ISIDORE, le moteur de recherche pour les SHS, et d’évaluer leur potentiel pour les services Huma-Num.
Pour mener cette expérimentation, le HN Lab a missionné l’entreprise DSI Global Services, mobilisant le data scientist Albeiro De Jesus Espinal Pulgarin. La société a proposé une démarche d’exploration en profondeur selon une approche progressive en dialogue avec l’équipe du HN Lab et en articulation avec les équipes des revues. La problématique scientifique initiale a été transposée en une sous-problématique adaptée à une approche d’analyse automatique : quels sont les concepts les plus pertinents et les plus caractéristiques d’un corpus donné ? En effet, établir une chaîne de traitement solide pour l’identification de ces concepts pertinents constitue un socle préalable pour élaborer une série d’analyses comparatives, quantitatives et qualitatives à différentes échelles. Ce sont sur ces bases que des éléments de réponse aux problématiques initiales sont susceptibles d’émerger. Cette recherche des concepts les plus pertinents a été systématiquement menée sur trois niveaux éditoriaux : l’article, le numéro (ou le dossier) et la revue elle-même. Ces paliers documentaires ont ouvert des échelles d’analyse tout à fait pertinentes, par exemple pour comprendre l’évolution du champ conceptuel d’une revue dans le temps.
Résultats
L’expérimentation a donné lieu à plusieurs résultats de nature et d’échelles diverses.
En premier lieu, le projet a permis de construire une chaîne complète et détaillée de traitement et d’analyse des corpus étudiés, en expérimentant plusieurs algorithmes de prédictions, et en explorant de manière poussée des voies d’amélioration de ces algorithmes. La chaîne est composée de différents modules sous forme de notebooks Python, articulant ainsi l’algorithmique et sa documentation.
En second lieu, la proposition de DSI s’est attachée à mettre en place une évaluation systématique de la chaîne de traitement selon trois dimensions, chacune comportant une série de métriques quantitatives.
- la dimension Machine/Deep Learning, dédiée à l’évaluation de la qualité des prédictions des concepts pertinents et à l’évaluation des vectorisations de mots existantes (word embeddings).
- la dimension Données, dédiée à l’évaluation de la pertinence d’ISIDORE pour l’application spécifique : exactitude, précision, consistance et intégralité, pour lesquelles ont été conçues des métriques de qualité pour l’ensemble des documents disponibles.
- la dimension Système, dédiée à l’évaluation des performances du système, en particulier la consommation en ressources des principaux modules du système (CPU, espace disque), du temps de traitement des articles et de la traçabilité des données.
Ces métriques ont permis de quantifier les améliorations progressives de la chaîne tout au long du projet.
En troisième lieu, le projet a mis en production une infrastructure complète, déployée sous docker et comprenant différentes plateformes pour le traitement des données (Jupyter Hub/Lab), l’annotation de corpus (Doccano), la visualisation des données analysées (Kibana basé sur Elastic Search) et la gestion des flux de données (Apache Airflow). Un espace Sharedocs interconnecté à l’infrastructure (via RCLONE) a permis la gestion des données et des données intermédiaires. À cette infrastructure s’ajoute un mini-site à destination des éditeurs et éditrices ayant participé aux évaluations « métiers » des prédictions de la machine.
Enfin, le projet a produit une grande quantité de données intermédiaires, issues des transformations du corpus, de leurs analyses terminologiques, de leurs vectorisations. Une partie de ces données est exploitée par la plateforme Kibana offrant des visualisations pré-paramétrées (dashboards) et un outil pour en produire de nouvelles. Ce dernier résultat constitue en fait le début d’une nouvelle phase d’analyse qualitative qui sera menée avec les éditeurs et éditrices des revues participantes.
En lien avec la mission du HN Lab au sein de l’IR*, l’expérimentation permet de formuler des pistes de travail pour l’IR* et plus particulièrement pour ISIDORE et sa chaîne d’indexation et d’enrichissement.
Chaîne de traitement
Le développement de la chaîne a été structuré en 5 étapes pour le traitement automatique de corpus de revue :
- Analyse des données
- Extraction des données
- Préparation des données
- Modélisation des données
- Évaluation des résultats

Illustration simplifiée de la chaîne d’analyse menée lors de l’expérimentation Revue 2.01
Analyse des données
L’expérimentation a porté sur les corpus de trois revues partenaires du projet Revue 2.0, Études Françaises, Intermédialités et Sens Public, dont les archives ont été fournies par Érudit au format XML Erudit.
Le développement réalisé fournit un ensemble de librairies, fonctions et approches utilisées pour l’analyse du corpus d’articles de chaque revue.
L’ensemble de notebooks développés permettent d’exécuter les actions suivantes à partir du corpus spécifique :
- Produire une analyse descriptive du corpus de la revue au format XML Érudit.
- Identifier les inconsistances présentes dans le corpus à partir de métriques de qualité du texte des articles.
- Analyser le type de contenu d’articles de revue.
- Analyser la terminologie de la revue pour chaque niveau éditorial : articles, numéros, ensemble de la revue.
- Analyser la terminologie de la revue par rapport aux référentiels ISIDORE.
Pour synthétiser, ces différents modules permettent de parcourir les principales dimensions du corpus de revue et d’identifier des possibles sources de bruit (générées le plus souvent lors du processus d’océrisation) susceptibles de réduire le niveau de performance des modèles Machine/Deep learning utilisés pour l’analyse approfondie des corpus.
Livrables
DataAnalysis/Analyse_descriptif_de_revues.ipynbDataAnalysis/Analyse_du texte.ipynbDataAnalysis/Analyse Terminologique.ipynbDataAnalyis/Tutoriel pour l'outilisation d'extraction terminologique.ipynbDataAnalysis/DataModel/TerminologyExplorer.pyDataAnalysis/DataModel/RevuePOO.pyDataAnalysis/Analyse des enrichissements ISIDORE.ipynb
Extraction des données
Le corpus de données initial a été livré par Érudit dans une structure arborescente de fichiers au format XML Erudit organisant les articles par dossier ou par numéro selon la revue. L’extraction a consisté à transformer chaque corpus en objets facilitant son traitement et l’automatisation de l’analyse, toujours selon la granularité éditoriale en article, numéro/dossier et revue. Cette étape a également permis d’estimer le niveau de qualité de traitement du corpus dans son format natif Érudit et de détecter des opportunités d’amélioration pour une description plus précise de la revue.
Les notebooks développés dans ce module permettent finalement de :
- Extraire le texte de chaque article de revue
- Extraire les métadonnées des articles/numéros/revues.
- Analyser les caractéristiques du format Érudit sur l’ensemble de la revue et le recouvrement des principales étiquettes XML utilisées par la plateforme Érudit.
Livrables
- Extraction du texte à partir du format XML via la classe Python
DataAnalysis/DataModel/RevuePOO.py
Préparation des données
Le module de préparation des données permet à un utilisateur ou une utilisatrice de réaliser les actions suivantes :
- Produire et exporter l’analyse syntaxique de chaque article de revue au format JSON.
- Produire et exporter le texte des articles sous la forme d’un graphe de connaissances comprenant l’ensemble de triplets identifiés sur ces textes.
- Réaliser des tests de connexion vers des moteurs existants de bases de données (ElasticSearch).
- Exporter vers une base des données le texte de chaque article de revue et l’ensemble de métadonnées par article/numéro/revue.
- Exporter la terminologie par article/numéro/revue vers un moteur de bases de données.
- Exporter la représentation vectorielle de chaque terme de la terminologie de la revue vers une base des données. Dans le cadre de cette expérimentation, l’exportation est illustrée à l’aide de divers notebooks qui représentent les termes de revue comme un vecteur produit par un modèle BERT.
- Réaliser des recherches sémantiques à grande échelle des termes de revue à partir d’un moteur de bases de données comme ElasticSearch.
- Exporter l’ensemble des entités nommées identifiées sur le texte des articles (personnes, localisations, organisations, etc.) vers un moteur de bases de données.
- Exporter les propositions d’enrichissements sémantiques réalisées par l’API d’ISIDORE sur l’ensemble des termes de la revue.
En d’autres mots, le module développé permet d’exporter l’ensemble des données pour l’analyse de la revue à partir d’un moteur de bases de données centralisant les différents éléments à grande échelle. Cette exportation permet aussi à l’utilisateur ou l’utilisatrice de réaliser des analyses plus approfondies et personnalisées à partir de l’outil de visualisation Kibana.
Livrables
DataExtraction/Exportation de l'analyse syntaxique des articles.ipynbDataExtraction/Exportation de revues vers le graphe de connaissances.ipynbDataExtraction/Processus d'Exportation des Données vers ElasticSearch.ipynb- Modules d’exportation des données placés dans le dossier
DataPreparation/Modules
Modélisation
L’étape de modélisation offre un ensemble de notebooks qui permettent de représenter les champs sémantiques de chaque revue selon différentes méthodes Machine/Deep learning. Sur la base des notebooks réalisés, un utilisateur ou une utilisatrice peut réaliser les actions suivantes :
- Identifier les principales thématiques de la revue à partir de deux types de modèles : Latent Dirichlet Allocation (Probabilité) et BERT (Analyse vectorielle).
- À partir d’une annotation de l’expert ou de l’experte sur les concepts les plus pertinents d’un article de revue, l’utilisateur ou l’utilisatrice peut identifier quelles sont les caractéristiques du texte associées à la perception de l’expert.
- L’utilisateur ou l’utilisatrice peut entraîner divers modèles Machine/Deep Learning pour l’extraction automatique de termes pertinents sur l’ensemble d’articles/numéros de la revue.
- Analyser la perception des experts sur la pertinence de termes de revue en mobilisant le cadre théorique de la logique floue.
- Représenter le texte des articles en graphe de connaissances sur la base d’une extraction de triplets sur le texte de chaque article. Ce graphe de connaissances peut être analysé sous trois dimensions : dimension syntaxique (relations explicites exprimées par les auteurs des articles), dimension sémantique (relations détectées à partir des enrichissements ISIDORE et des modèles de similarité sémantique comme BERT) et dimension terminologique (relations identifiées à partir de l’analyse terminologique effectuée sur la revue).
- Détecter des communautés de connaissances à partir de l’extraction de termes pertinents sur l’ensemble d’articles de la revue.
- Comparer les communautés de connaissances détectées sur la revue avec des communautés similaires sur d’autres revues.
- Visualiser les communautés de connaissances à partir d’algorithmes de visualisation de graphes.
- Caractériser les relations de l’ensemble de triplets extraits sur le texte des articles.
- Résoudre et extraire les coréférences présentes dans le texte de chaque article à partir du modèle BERT. C’est une étape fondamentale pour l’approfondissement dans l’analyse du discours à partir du texte de chaque article.
- Représenter et visualiser les champs sémantiques de la revue à partir d’un processus de clustering effectué sur les termes les plus pertinents de chaque article de revue.
- Estimer le nombre optimal de champs sémantiques de la revue à partir de métriques statistiques comme le statistique Gap.
- Analyser la qualité des clusters de connaissances obtenus à partir de l’action précédente.
- Visualiser l’évolution de ces champs sémantiques tout au long de l’histoire de la revue.
- Projeter les clusters de connaissances sur diverses dimensions d’analyse. Par exemple, un cluster identifié peut être projeté sur la terminologie de la revue pour évaluer comment ce cluster a évolué dans le temps du point de vue terminologique.
En synthèse, le module de modélisation permet d’explorer plus en profondeur le contenu de chaque revue et de représenter leurs connaissances sous le concept de champ sémantique afin de permettre à un expert ou à une experte d’interpréter et de décrire quels ont été les principaux apports de la revue en termes de connaissances dans son domaine spécifique.
Livrables
Définir les modèles machine/deep learning pour la prédiction de la pertinence de termes/concepts par article/revue:
Modeling/Exploration du concept de pertinence.ipynbModeling/Exploration des caractéristiques du texte associés à l'annotation de l'expert. Modélisation.ipynbModeling/Exploration des caractéristiques du texte associés à l'annotation de l'expert. Modélisation Logique Floue.ipynbModeling/DiscourseAnalysis/Reconstruction du flux du discours.ipyb
Définir les modèles machine/deep learning pour la discrimination de champs sémantiques. Formalisation du concept de champ sémantique:
- Discrimination à partir du graphe de connaissances :
Modeling/SemanticFields/Formalisation du concept de champ sémantique.ipynb - Discrimination à partir du clustering BERT :
Modeling/ISIDORE/SemanticFields/Clustering de connaissances à partir de BERT-Revue X.ipynb
Formaliser le concept de champ sémantique par article, par revue, par champ disciplinaire et par le référentiel ISIDORE:
- Extraction de triplets à partir du texte de l’article :
Modeling/SemanticFields/ExtractionTripletsV2.ipynb Modeling/SemanticFields/Formalisation du concept de champ sémantique.ipynb
Évaluation
Le module d’évaluation rassemble les différentes évaluations effectuées sur le projet, en lien avec les experts ou expertes mobilisé·e·s (éditeurs et éditrices des revues). Dans ce module, le rôle de l’expert ou de l’experte est essentiel pour évaluer et contrôler tout au long de son cycle de vie la qualité du système. Ce module comprend les actions suivantes :
- Annoter les termes les plus pertinents d’un article, ce qui sert comme source de données pour l’identification de caractéristiques du texte associées au concept de pertinence de l’expert.
- Suivre l’évolution de la qualité des modèles d’extraction automatique de termes pertinents. Comparer différentes versions de modèles à partir de diverses métriques de qualité comme la « Métrique de niveau de perception humaine du modèle IA ».
- Évaluer le niveau de recouvrement des référentiels d’ISIDORE par rapport à la terminologie de la revue.
- Produire des tests pour l’évaluation de la pertinence des propositions d’enrichissement sémantique obtenues à partir de l’API d’ISIDORE.
- Analyser les annotations humaines par rapport à l’extraction automatique de termes pertinents réalisée par la machine.
- Générer divers tests, par exemple un test sur la pertinence de type de contenus des articles pour décrire ses apports en connaissances.
- Suivre la consommation du système en termes de ressources (Stockage, temps de traitement et mémoire RAM).
Le module d’évaluation constitue une base pour l’évaluation du système tout au long de sa durée de vie. L’intervention humaine régulière (experts métiers et experts techniques) est fondamentale pour suivre la qualité du système dans son intégralité sur la base 1) de tests générés aléatoirement et 2) d’un ensemble de métriques de qualité définies pour les différentes dimensions de la chaîne de traitement.
Livrables
Définir les métriques de qualité pour l’évaluation de l’ensemble de modules du système:
Documentation/Quality/Proposition d'Indicateurs Revue 2_0 - DSI Group 2021.pdfQuality/System Quality Supervision.ipynb
Définir le protocole d’évaluation:
- Documentation/Quality/diagramme de séquences du protocole.png
- Site web de publication de tests : https://nsauret.gitpages.huma-num.fr/r20-eval/
- Création de tests et distribution aux évaluateurs et évaluatrices
- Plateforme Doccano (annotation d’article par l’humain pour l’identification de termes pertinents)
- Analyse d’annotation d’experts ou d’expertes :
Quality/ExpertTests/ExpertAnnotationsAnalysis.ipynb - Analyse de la pertinence de contenus d’articles de revue :
Quality/ExpertTests/Sprint0/PertinenceDesContenus_Validation.ipynb - Analyse terme par terme des annotations d’experts ou d’expertes :
Quality/ExpertTests/TermbyTermAnalysis.ipynb
Évaluation du module d’extraction des données:
- Évaluation de l’extraction terminologique :
Quality/ExpertTests/TestExtractionTerminologique.ods
Évaluation de la pertinence des principaux référentiels d’ISIDORE par rapport à la problématique métier:
- Évaluation du recouvrement d’ISIDORE sur les revues :
Quality/ISIDORE/ISIDORE Evaluation 1.ipynbQuality/ExpertTests/ApprovedTests/MD3 QA PertinenceISIDORE.ipynb
- Analyse de la pertinence d’enrichissements :
DataAnalysis/Analyse des enrichissements ISIDORE.ipynb
- Proposition d’un filtre plus strict pour l’amélioration de la pertinence d’enrichissements :
Modeling/ISIDORE/Modèles pour l'amélioration de la pertinence de propositions ISIDORE. Interface Utilisateur.ipynb
Évaluation des modèles IA:
- Évaluation des modèles supervisés :
Modeling/Exploration des caractéristiques du texte associés à l'annotation de l'expert. Modélisation.ipynb - Évaluation des modèles pour la prédiction de termes pertinents :
Quality/System Quality Supervision.ipynb - Évaluation de modèles pour l’extraction terminologique :
Quality/ExpertTests/TestExtractionTerminologique.ods
Évaluation
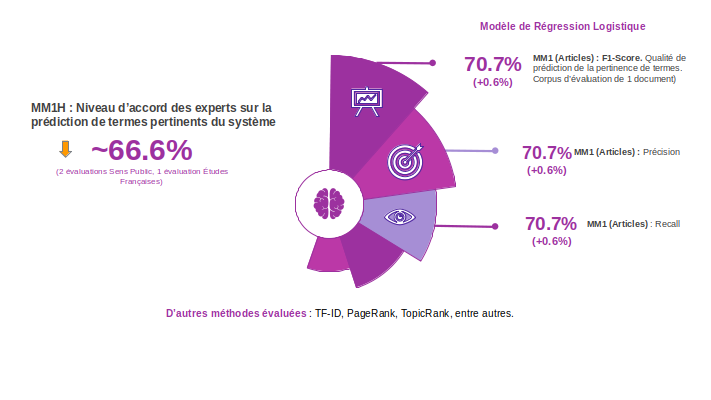
Dimension Machine/Deep Learning
Cette dimension se consacre à l’évaluation de la qualité des prédictions des concepts pertinents et à l’évaluation des vectorisations de mots existantes (word embeddings).
Évaluation finale sur la dimension Machine/Deep Learning
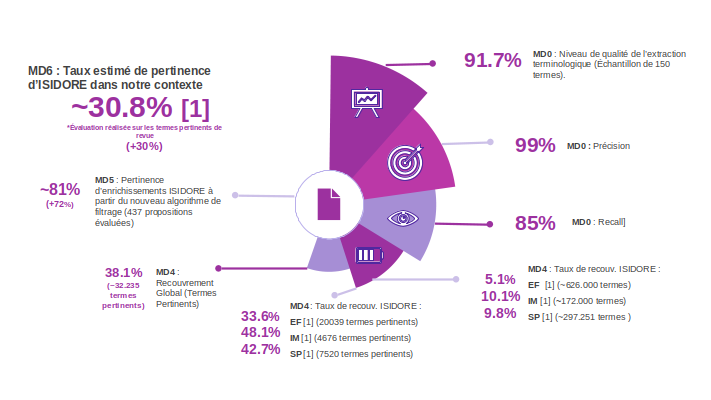
Dimension Données
Cette dimension se consacre à l’évaluation de la pertinence d’ISIDORE pour l’application spécifique : exactitude, précision, consistance et intégralité, pour lesquelles ont été conçues des métriques de qualité pour l’ensemble des documents disponibles.
Évaluation finale sur la dimension Données
Dimension Système
Cette dimension se consacre à l’évaluation des performances du système, en particulier la consommation en ressources des principaux modules du système (CPU, espace disque), du temps de traitement des articles et de la traçabilité des données.
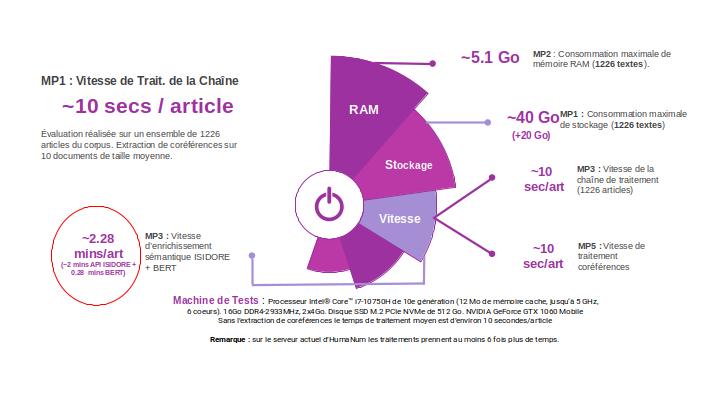
Évaluation finale sur la dimension Système
Infrastructure
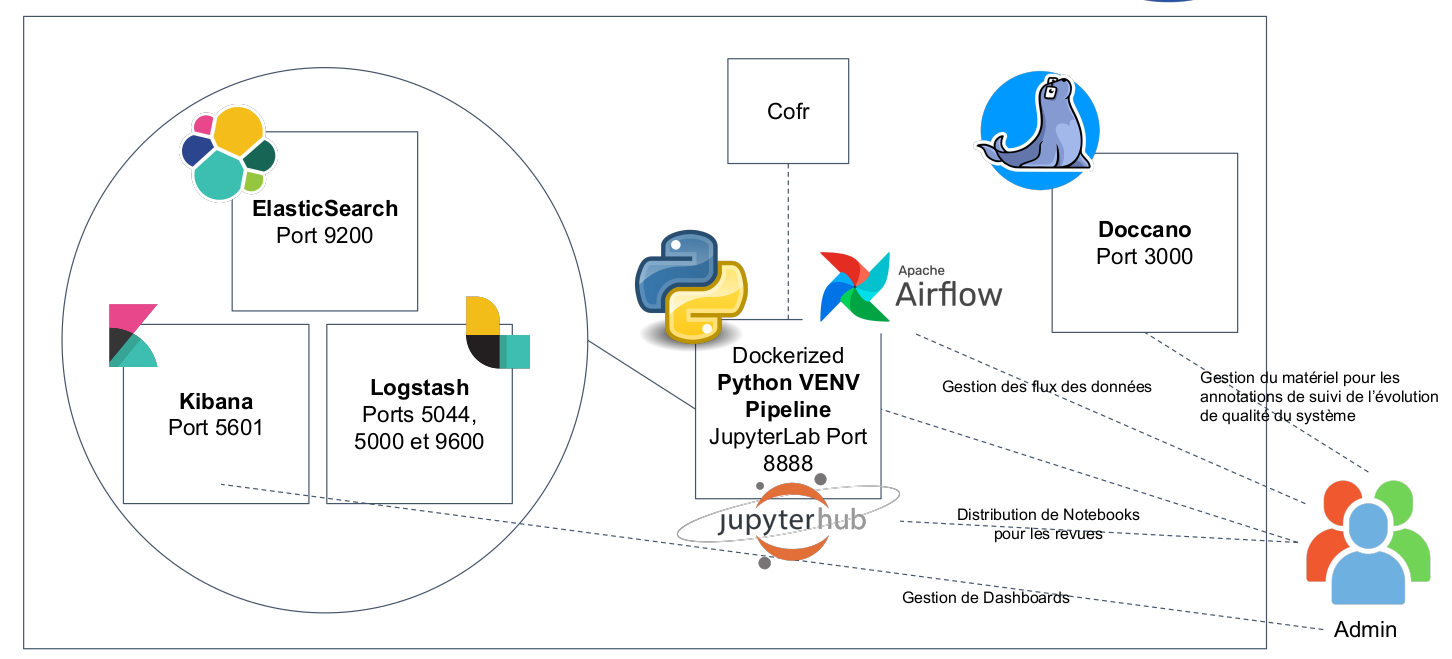
Schéma de l’infrastructure Docker
L’architecture du système consiste à une infrastructure Docker constituée par les composantes suivantes :
- ElasticSearch : container ElasticSearch qui contient le principal moteur de bases de données pour la gestion de données de revue à grande échelle.
- Kibana : outil d’analyse des données pour ElasticSearch. Kibana permet aux utilisateurs et utilisatrices d’approfondir sur les données de la revue qui sont exportés et de créer des Dashboards au fur et à mesure de leurs besoins.
- Logstash : logiciel qui permet d’enregistrer tout type de logs générés par le système. Cela permet notamment d’identifier la source des bugs qui peuvent arriver pendant la future mise en production du système.
- JupyterLab : container qui permet à un utilisateur ou une utilisatrice d’exécuter l’ensemble de notebooks du projet sur un serveur ou sur sa machine locale.
- JupyterHub : container qui permet de distribuer des Notebooks dans un environnement multi-utilisateur·trice. Il est accompagné par NBGitpuller pour faciliter la distribution de Notebooks via Gitlab.
- Doccano : container qui contient la plateforme Doccano. Cette plateforme facilite l’annotation collaborative des documents. Dans le cadre du projet, elle a été utilisée pour l’exploration du concept de pertinence de termes du point de vue de la perception des experts.
- Airflow : plateforme de gestion de flux des données qui permet de créer des flux des données pour l’exécution séquentielle ou parallèle de l’ensemble de modules qui ont été développés.
- ShareDocs : la plateforme ShareDocs est utilisée pour la synchronisation des données initiales et intermédiaires à grande échelle.
Le système peut être installé sur un serveur Apache (expérimentations online) ou sur une machine locale (expérimentations offline).
Intérêts et transferts pour les services de la TGIR Huma-Num
L’expérimentation menée par le HN Lab avec la collaboration de l’équipe de DSI Groups permet de formuler des pistes de travail et d’amélioration des propres services de la TGIR, en particulier pour les chaînes d’enrichissements multilingues des métadonnées et données traitées dans ISIDORE. Cette expérimentation a permis de confronter les enrichissements effectués dans ISIDORE, qui ont une vocation documentaire (car calculé avec des référentiels sur des métadonnées), à une extraction de connaissances par apprentissage de contenus scientifiques (ou « &nbps;contenus métiers&nbps; ») directement depuis le texte intégral des revues. L’intérêt de ce type de travaux est aussi de mesurer l’impact qu’il peut avoir sur un écosystème fondé sur l’usage d’API. L’API d’ISIDORE ayant été fortement sollicitée, l’expérimentation a permis d’alimenter les réflexions et les travaux d’Huma-Num, notamment dans le cadre d’Huma-Num Science Ouverte (HNSO), pour en améliorer les performances.
Ces travaux ont fait l’objet d’une réunion commune entre DSI Groups, le HN Lab et le pôle Accès de la TGIR Huma-Num pour partager l’expérience accumulée.
-
Tous les visuels ont été créés par Albeiro De Jesus Espinal Pulgarin, data scientist sur le projet. ↩